Replicação e Tolerância a Faltas
Introdução a sistemas replicados
A replicação consiste no processo de manter cópias de dados e software de um serviço em várias máquinas.

Benefícios de replicar um sistema
- melhor disponibilidade: mesmo que alguns nós falhem ou fiquem indisponíveis devido a falhas na rede, o sistema continua disponível
- melhor desempenho e escalabilidade:
- Podem existir cópias mais próximas do cliente
- Algumas operações não precisam de ser executadas sobre todo o sistema, podendo ser executadas apenas sobre algumas cópias (distribuindo assim a carga e aumentando a escalabilidade)
Linearizabilidade
Uma das garantias essenciais que um sistema replicado tem que assegurar é a coerência. O ideal seria um cliente ler a versão mais recente do recurso sempre que lê de uma réplica (mesmo que essa versão tenha sido escrita noutra réplica). Um critério de coerência que podemos utilizar é a linearizabilidade. Antes de definirmos o que é, é necessário ter em conta o seguinte quanto à ordenação de operações:
- As operações realizadas sobre um sistema replicado não são instantâneas:
- A operação é invocada por um cliente, executada durante algum tempo e o cliente só recebe a resposta mais tarde.
- Se uma operação X começa depois de outra operação Y acabar, então X ocorre depois de Y
- Se uma operação X começa antes de outra operação Y acabar, então X é concorrente com Y
Exemplo

- A concorrente com B
- A anterior a C
- B anterior a C
- C concorrente com D
- C anterior a E
- D concorrente com E
Definição
Um sistema replicado diz-se linearizável se e só se:
-
Existe uma serialização virtual que respeita o tempo real em que as operações foram invocadas, isto é:
- Se ocorre antes de (em tempo real), então tem de aparecer antes de na serialização virtual. (se e forem concorrentes, a serialização pode ordená-las de forma arbitrária)
-
A execução observada por cada cliente é coerente com essa serialização (para todos os clientes), ou seja:
- Os valores retornados pelas leituras feitas por cada cliente refletem as operações anteriores na serialização
Exercício
Considere os seguintes exemplos em que um cliente escreve sobre um inteiro replicado. Quais das execuções são serializáveis?
Exemplo 1:
Exemplo 2:
Exemplo 3:

R: Apenas o 1º exemplo:

Registos partilhados e replicados
Um registo suporta duas operações:
- Escrita:
- uma escrita substitui o valor da anterior
- apenas um cliente pode escrever no registo num dado instante, ou seja, as escritas são ordenadas
- Leitura:
- múltiplos clientes podem ler do registo ao mesmo tempo
Tipos de registos
Lamport definiu três modelos de coerência para registos:
-
Safe:
- Se uma leitura não for concorrente com uma escrita, lê o último valor escrito
- Se for, pode retornar um valor arbitrário
-
Regular:
- Se uma leitura não for concorrente com uma escrita, lê o último valor escrito
- Se for, ou retorna o valor anterior ou o valor que está a ser escrito
- NOTA: este tipo de registo não é linearizável, já que enquanto decorre uma escrita, é possível que leituras seguidas leiam sequências incoerentes de valores (primeiro o novo valor e depois o antigo)
-
Atomic:
- Equivalente a linearizabilidade quando aplicada a registos
- O resultado da execução é equivalente ao resultado de uma execução em que todas as escritas e leituras ocorrem instantaneamente num ponto entre o início e o fim da operação
Exemplos
- registo "Unsafe":

- registo "Safe":

- registo "Regular":

- registo "Atomic":
De onde surgiu a ideia de um registo "safe"?
Considere um registo com o valor (em binário: ) e que se quer escrever o valor (em binário: ). Se não existir um mecânismo de sincronização que impeça o leitor de ler o registo durante a escrita, a leitura pode retornar um dos seguintes valores:
- =
- =
- =
- =
(já que os bits são alterados individualmente em instantes diferentes)
Registos distribuídos
Uma forma de implementar registos distribuídos é a seguinte:
- Cada processo mantém uma cópia do registo
- Cada registo guarda um tuplo
<valor, versão> - Para executar uma operação (leitura ou escrita), os processos trocam mensagens entre si
É possível implementar este funcionamento de forma a que seja tolerante a faltas e não bloqueante!
Algoritmo ABD
Registo regular (com um só escritor):
-
Escrita:
- O escritor incrementa o número de versão e envia o tuplo
<valor, versão>para todos os processos. - Quando os outros processos recebem esta mensagem, atualizam a sua cópia do registo (caso seja uma versão mais recente que a local) e enviam uma confirmação ao escritor.
- A operação termina quando o escritor receber resposta de uma maioria.
- O escritor incrementa o número de versão e envia o tuplo
-
Leitura:
- O leitor envia uma mensagem a todos os processos solicitando o tuplo mais recente
- Cada processo envia o seu tuplo
<valor, versão> - Após receber resposta de uma maioria, retorna o valor mais recente e atualiza o valor local (caso necessário)

Exemplo

O algoritmo não é atómico

Tal como ilustrado no diagrama, é possível obter leituras diferentes consoante as réplicas que contactamos (lendo , depois e novamente), violando o princípio da linearizabilidade.
Registo atómico (com um só escritor):
-
Escrita:
- Idêntico ao anterior.
-
Leitura:
- Executa o algoritmo de leitura anterior mas não retorna o valor
- Executa o algoritmo de escrita, usando o valor lido
- Retorna o valor lido apenas após a escrita ter terminado
Espaço de Tuplos
Espaço de Tuplos "Linda"
Consiste num espaço partilhado que contêm um conjunto de tuplos (ex: <"A">,
<"A", 1>, <"A", "B">) e que suporta 3 operações:
Put: adiciona um tuplo (sem afetar os tuplos existentes) no espaçoRead: retorna o valor de um tuplo (sem afetar o conteúdo do espaço)Take: também retorna um tuplo mas remove-o do espaço- Tanto
ReadcomoTakesão bloqueantes caso o tuplo não exista - Tanto
ReadcomoTakeaceitam wildcards:Read(<"A", *>)pode retornar<"A", 1>ou<"A", "B">
Como o Take é bloqueante, pode ser usado para sincronizar processos:
- Elege-se um tuplo especial, por ex.
<lock>. - Cada processo remove o tuplo do espaço antes de aceder à região crítica e volta a colocá-lo no fim, garantindo assim exclusão mútua
- Conseguimos assim através de uma única interface partilhar memória e sincronizar processos
Enquanto que nos registos uma escrita fazia override do valor antigo, aqui o
processo equivalente é realizar um Take seguido de um Put (os tuplos são
imutáveis). O Take permite fazer operações que em memória partilhada requerem
uma instrução do tipo
compare-and-swap.
Nota
Note que as operações Put, Read e Take são conhecidas como out, rd e
in no modelo Linda, usamos estes nomes mais descritivos como simplificação.
Xu-Liskov
Muitas das implementações de espaços de tuplos adotam uma solução centralizada. Isto tem vantagens em termos de simplicidade, mas tais soluções não são tolerantes a falhas nem escaláveis.
Xu-Liskov é uma implementação distribuída e tolerante a faltas do "Linda".
Algumas observações prévias
-
A tolerância de faltas pressupõe um serviço de filiação que gere o grupo de réplicas:
- Quando uma réplica falha, a filiação do grupo é alterada
-
Sendo assim, quando o algoritmo espera por "todas" as respostas ou pela maioria delas, refere-se à filiação do grupo num dado instante.
-
Esta alteração dinâmica da filiação é um problema bastante complexo por si só e portanto não vai ser abordado
-
Os autores optam por usar UDP (portanto pode haver perda de mensagens), sendo o próprio algoritmo responsável por retransmitir mensagens.
- Solução modular: usar TCP
O objetivo dos autores com este design era obter a solução mais eficiente e com o menor tempo de resposta possível, mas assegurando linearizabilidade.
Funcionamento do algoritmo
Put:
- The requesting site multicasts the
putrequest to all members of the view; - On receiving this request, members insert the tuple into their replica and acknowledge this action;
- Step 1 is repeated until all acknowledgements are received. For the correct operation of the protocol, replicas must detect and acknowledge duplicate requests, but not carry out the associated put operations.
Read:
- The requesting site multicasts the
readrequest to all members of the view; - On receiving this request, a member returns a matching tuple to the requestor,
- The requestor returns the first matching tuple received as the result of the operation (ignoring others);
- Step 1 is repeated until at least one response is received.
Take:
Phase 1: Selecting the tuple to be removed
- The requesting site multicasts the
takerequest to all members of the view; - On receiving this request, each replica acquires a lock on the associated tuple
set and, if the lock cannot be acquired, the
takerequest is rejected; - All accepting members reply with the set of all matching tuples;
- Step 1 is repeated until all sites have accepted the request and responded with their set of tuples and the intersection is non-null;
- A particular tuple is selected as the result of the operation (selected randomly from the intersection of all the replies);
- If only a minority accept the request, this minority are asked to release their locks and phase 1 repeats.
Phase 2: Removing the selected tuple
- The requesting site multicasts a remove request to all members of the view citing the tuple to be removed;
- On receiving this request, members remove the tuple from their replica, send an acknowledgement and release the lock;
- Step 1 is repeated until all acknowledgements are received.
Visto que este algoritmo foi projetado para minimizar o delay :
- Operações
readapenas bloqueiam até que a primeira réplica responda ao pedido - Operações
takebloqueiam até o final da fase 1, quando o tuplo a ser excluído foi acordado - Operações
putpodem retornar imediatamente
No entanto, isto introduz níveis inaceitáveis de concorrência. Por exemplo, uma
operação read pode aceder a um tuplo que deveria ter sido excluído na segunda
fase de uma operação take. Assim, são necessárias as seguintes restrições adicionais:
- As operações de cada worker devem ser executadas em cada réplica na mesma ordem em que foram emitidas pelo worker
- Uma operação
putnão deve ser executada em nenhuma réplica até que todas as operaçõestakeanteriores, emitidas pelo mesmo worker, tenham sido concluídas em todas as réplicas (na visão do mesmo)
Nota
Operações
takebloqueiam até o final da fase 1, quando o tuplo a ser excluído foi acordado
Note que isto é uma otimização para minimizar a latência, no algoritmo original o worker fica bloqueado até o final da fase 2. Esta otimização não faz parte do projeto.
Exemplos
Read:

Put:

Take:
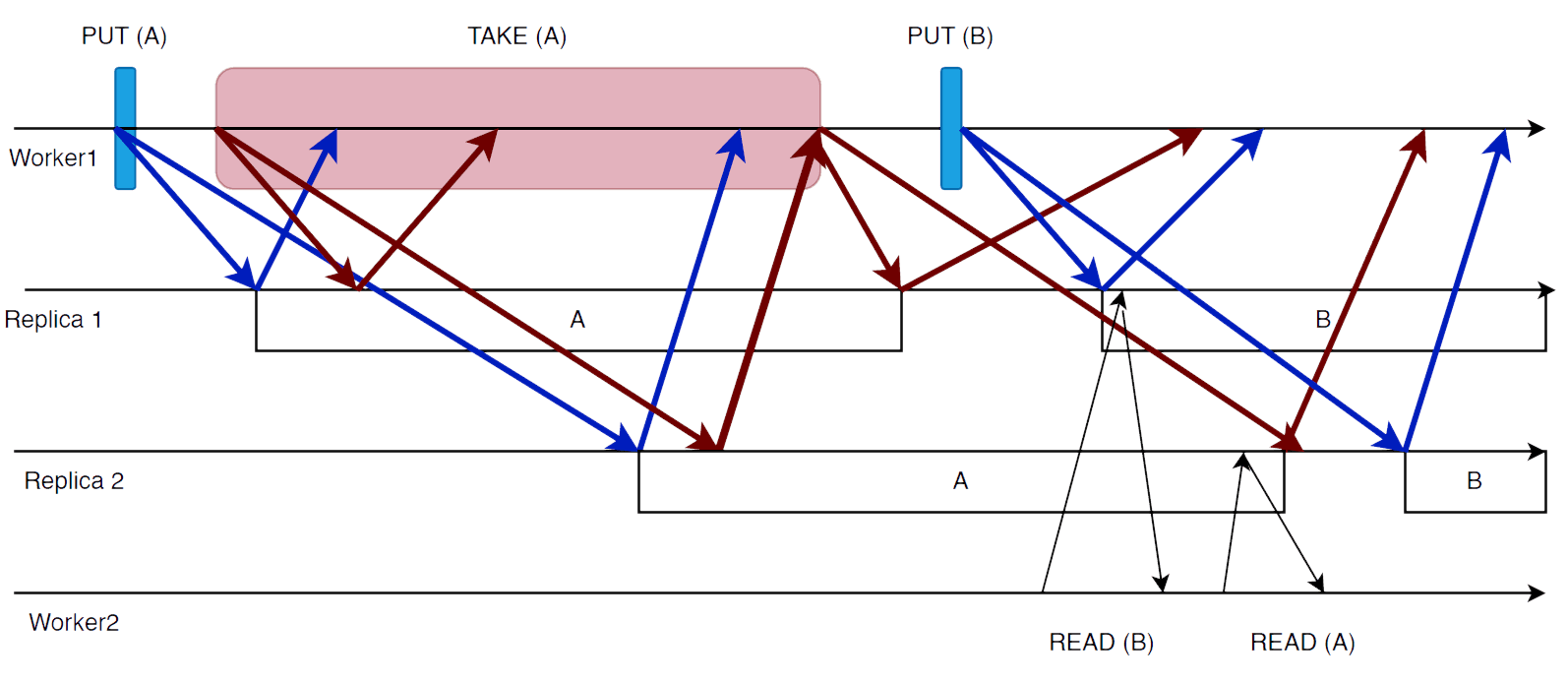
Imaginemos que o Read não era bloqueante, ou seja, ou retornava o tuplo
ou "null". O sistema continuaria a ser linearizável? Não, pois seria possível:
- Um cliente executa
Putde um tuplo - Um cliente executa
Read(t)várias vezes, concorrentemente com oPut - Se o leitor recebe respostas de réplicas diferentes em cada
Read, pode ler e de seguida "null"
Quanto ao Take, é possível que dois processos tentem fazer Take do mesmo tuplo
concorrentemente e nenhum consiga a maioria (deadlock). Para resolver este problema
introduz-se um fator de aleatoriedade: cada processo repete o seu pedido um tempo
aleatório depois (solução não determinista).
Referências
- Coulouris et al - Distributed Systems: Concepts and Design (5th Edition)
- Secção 6.5
- Departamento de Engenharia Informática - Slides de Sistemas Distribuídos (2023/2024)
- SlidesTagus-Aula05
- SlidesAlameda-Aula05